The Balancing Act: unmasking and alleviating ASR Biases in Portuguese
In the field of spoken language understanding, systems like Whisper and Multilingual Massive Speech (MMS) have shown state-of-the-art performances. This study is dedicated to a comprehensive exploration of the Whisper and MMS systems, with a focus on assessing biases in automatic speech recognition (ASR) inherent to casual conversation speech specific to the Portuguese language. Our investigation encompasses various categories, including gender, age, skin tone color, and geo-location. Alongside traditional ASR evaluation metrics such as Word Error Rate (WER), we have incorporated p-value statistical significance for gender bias analysis. Furthermore, we extensively examine the impact of data distribution and empirically show that oversampling techniques alleviate such stereotypical biases. This research represents a pioneering effort in quantifying biases in the Portuguese language context through the application of MMS and Whisper, contributing to a better understanding of ASR systems’ performance in multilingual settings.
Table of Contents
- Introduction
- Contributions
- Dataset Statistics
- Results & Analysis
- Character Error Rate Analysis on Categories
Introduction
To explore the biases present in multilingual ASR systems trained on extensive speech data, we investigated variants of OpenAI’s Whisper ASR system and Meta AI’s MMS ASR system, both of which have achieved state-of-the-art performance levels. In addition, we selected the Casual Conversation Dataset version 2 (CCD V2) to quantify biases and assess the fairness of these system performances in the context of the Portuguese language. Our study takes into account a diverse spectrum of categories, including age groups, gender, geographical locations, and skin tones. The consistency in textual content across all CCD V2 recordings establishes a robust basis for the efficient evaluation of system performance across a broad array of categories. Only a limited number of studies have delved into the influence of state-of-the-art multilingual ASR systems on domain-specific ASR tasks. For example, these studies have explored code-switching between languages using systems like Whisper and MMS, or they have examined the effects of ASR errors on discourse models among groups of students in noisy, real-world classroom settings between Whisper and Google ASR system.
More often, an imbalanced distribution of evaluation data across various sub-categories can result in an inadequate analysis of the evaluation process itself. Therefore, we have introduced this study along with explore two resampling methods, namely, naïve and Synthetic Minority Oversampling Technique (SMOTE), to ensure a balanced data distribution across each subgroup when quantifying the biases. In the assessment of ASR systems, our primary choice of metrics includes Word Error Rate (WER) and Character Error Rate (CER). Interestingly, we observe that oversampling techniques can alleviate performance disparities between certain subgroups.
Contributions
The main contributions of this paper are as follows:
- It presents the first study on analyzing disparities within multilingual ASR systems focused on the Portuguese language.
- It emphasizes the critical significance of data distribution among sub-categories by employing oversampling techniques.
- It illustrates the comparative distinctions between Whisper ASR and MMS ASR, and examines the impact of model parameters on developing an efficient system design.
- Besides gender and age groups, it investigates skin tone and geo-location as criteria to measure inter-racial biases.
Results and Analysis:
Gender
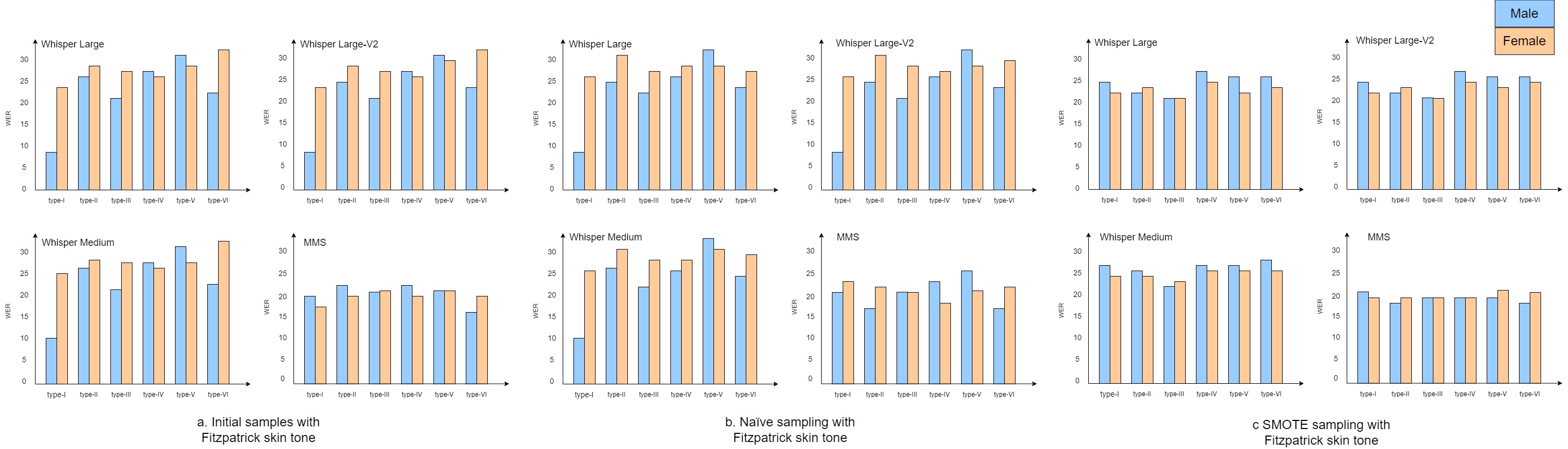
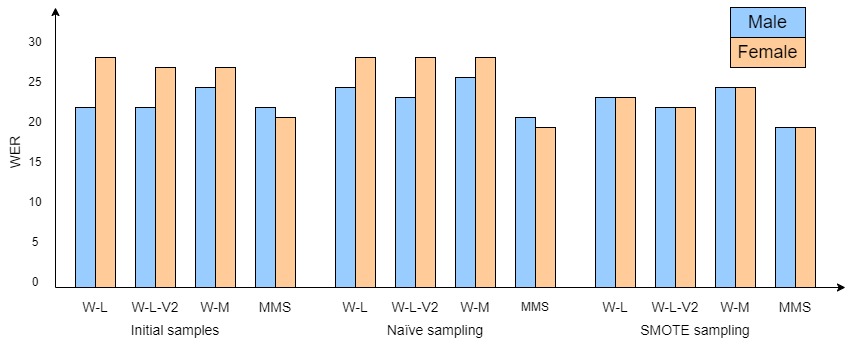
Significant disparities are evident across different skin tone types between male and female individuals. Specifically, within the Whisper ASR variants, notable performance differences are observed for skin-tone type-I and type-VI. In these cases, the male subgroup exhibits better WER compared to the female subgroup, particularly in the context of initial samples and naïve sampling approaches. Moreover, the MMS ASR system demonstrates a relatively even distribution of WER across all skin-tone types and outperforms all variants of the Whisper ASR. It is worth highlighting that, across all the ASR systems under examination, the use of SMOTE sampling has consistently played a role in mitigating performance disparities, leading to more balanced outcomes across gender subgroups.
Skin-tone
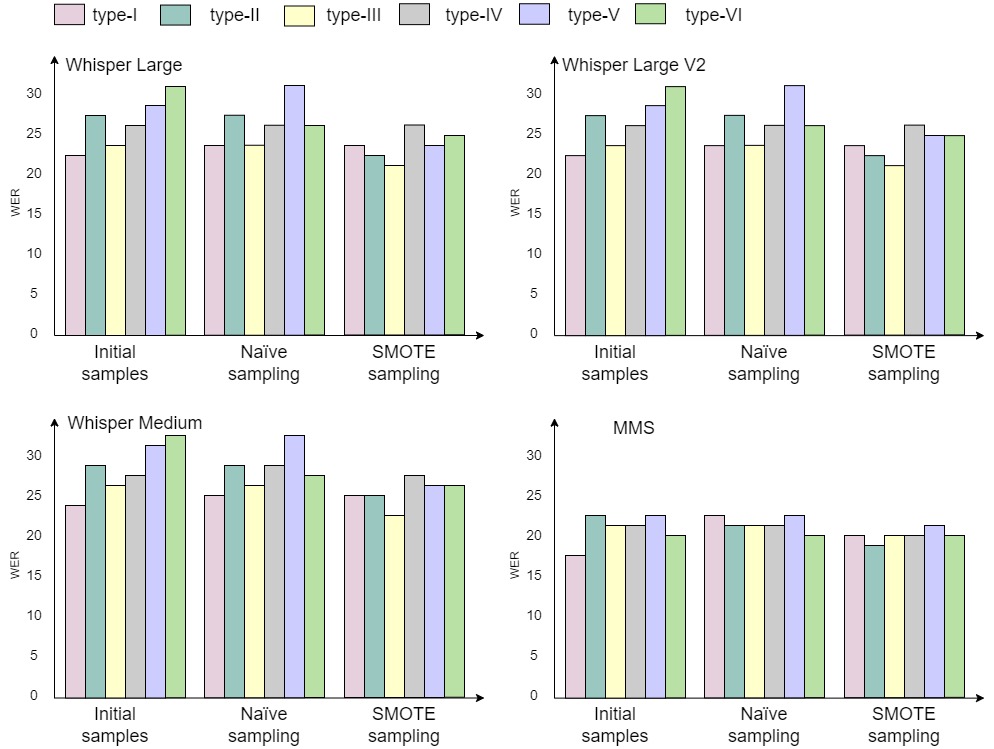
We observe that individuals with skin types I to III demonstrate comparatively better WER than those with skin type IV. This observation sheds light on potential racial biases in ASR systems, where greater skin-type variations often indicate darker skin colors.
However, amidst these disparities, the MMS ASR system stands out with evenly distributed WER measures across all skin-type scales. When assessing the differences introduced by sampling approaches, initial samples, and naïve sampling reveal disparities among skin-tone subgroups. In contrast, the consistent use of SMOTE sampling proves effective in mitigating discrepancies across all the ASR systems under investigation.
Age Group
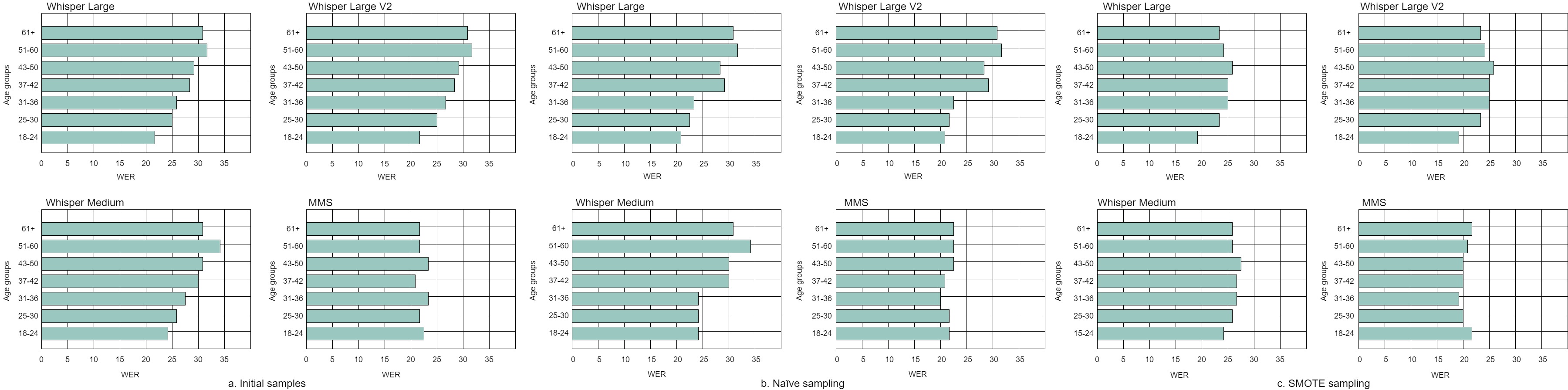
In Figure 4, we present an age group analysis of the Portuguese language for ASR systems using three different sampling techniques: initial samples, naïve sampling, and SMOTE sampling. Across all the sampling methods, the MMS ASR system consistently maintains WER measures below 25% for all age groups, exhibiting a relatively even distribution of WER values. In contrast, the Whisper ASR variants demonstrate disproportionate WER measures, particularly noticeable between the age groups of 18-36 and 36+. Moreover, the performance of the Whisper ASR degrades as age groups increase. However, the utilization of SMOTE sampling significantly improves the WER of the Whisper systems, bringing it to an overall 25%.
This distinctively highlights the positive impact of SMOTE sampling in reducing performance disparities across various age groups for both the Whisper and MMS ASR systems.
Geolocation
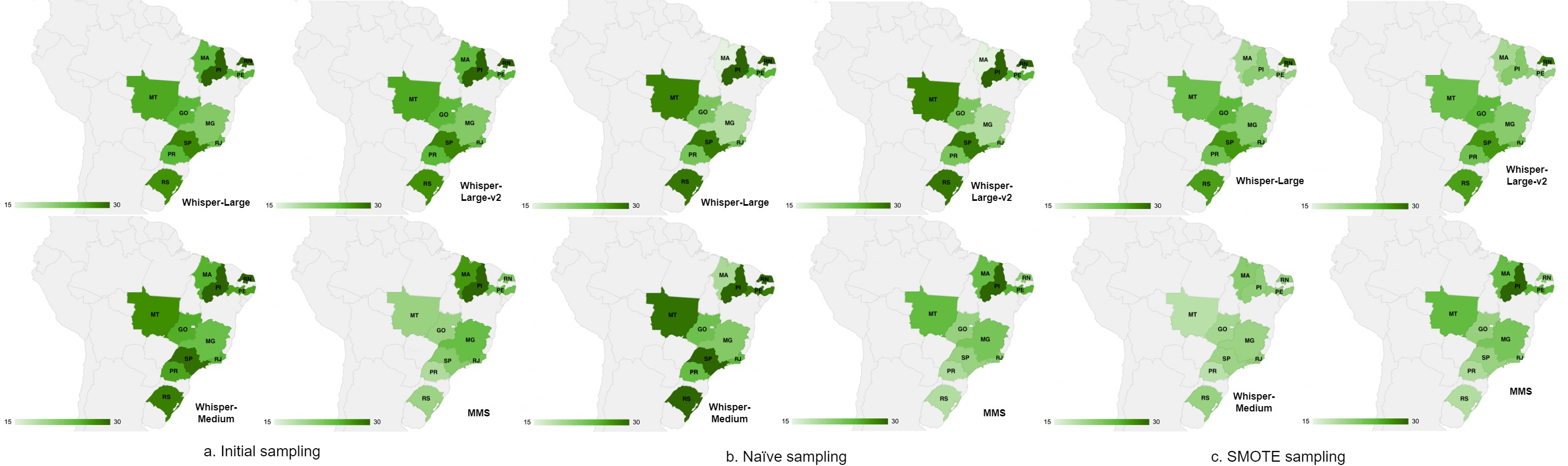
Figure 5 provides a comprehensive examination of the impact of different sampling techniques on ASR performance disparities across various regions in Brazil. Notably, when considering the Whisper ASR system, regions such as São Paulo (SP), Piauí (PI), Rio Grande do Norte (RN), and Rio Grande do Sul (RS) are notably affected by performance differences, regardless of whether initial samples or naïve sampling methods are employed. These regions exhibit significant variations in WER compared to other regions. Overall, the MMS ASR system displays a more even distribution of evaluation measures across all sampling approaches and generally outperforms the Whisper ASR variants. Furthermore, it is notable to highlight that, despite observing proportionate WERs across most regions in Brazil, the MMS ASR system experiences a decline in performance, specifically in the Piauí (PI) region for all sampling approaches.
Even after the application of SMOTE sampling, the Whisper ASR variants continue to exhibit consistently higher WER values in the Rio Grande do Norte (RN) region. However, SMOTE sampling effectively mitigates WER discrepancies in the Piauí (PI) region. This underscores the distinct challenges posed by regional variations in ASR performance and underscores the potential of SMOTE sampling in addressing these disparities.